Spring Boot下通过EntityManagerFactoryDependsOnPostProcessor来确保Flyway的初始化执行晚于JPA。但是有时候我们会希望由JPA完成表结构的维护,Flyway用来修数据、基础数据的维护。这个时候如果flyway执行早于JPA的表结构维护,可能会导致表或字段不存在的异常。 所以我们重新实现FlywayMigrationStrategy的逻辑,在正常migrate时,不做具体事情,把flyway保存下来,在Spring完成初始化后ContextRefreshedEvent再执行migrate。
Nginx的配置是一种声明式的配置,虽然有if指令,但是跟传统意义上的编程语言是完全不同的。在实际使用的过程中,使用if指令会产生有很多很奇怪的事情,由其是在对它没有充分了解之前,经常会误用。Nginx官方也提醒在location里使用if是灾难,如果一定要使用if,需要测试测试再测试. If is Evil… when used in location context 对于声明式的配置来说: 1. Nginx的if指令条件满足时,会在if块里创建一个嵌套的子location块,然后再执行if块内的声明和内容处理器(content handler)。 2. 在一个配置块里只有一个if语句和一些其他的声明,由于if的存在,会导致有些声明不生效。为了保证这些声明都生效,最好在if块内,重新声明一次。 3. 在一个配置块里,如果有两个if指令都满足条件,只有第二个if会被执行。 Case 1
1 2 3 4 5 6 7 8 9 10 11 12
location /case1 { set $a 32; if ($a = 32) { set $a 56; } set $a 76; proxy_pass http://127.0.0.1:$server_port/$a; }
dorado可以自定义控件,所以dorado ide 在设计的时候并没有把控件写死,而是采用基于配置的方式来加载控件及控件对应的事件、属性。 dorado配置规则是基于当前项目动态生成的,然后保存在项目根目录的.rules文件里。控件对应的图标则保存在.setting目录里。这个设计也带来了弊端–每个新项目都要手动更新一下dorado配置规则。 dorado的配置规则更新有两方式:离线、在线。
org.springframework.security.web.firewall.RequestRejectedException: The request was rejected because the URL contained a potentially malicious String "//" at org.springframework.security.web.firewall.StrictHttpFirewall.rejectedBlacklistedUrls(StrictHttpFirewall.java:369) at org.springframework.security.web.firewall.StrictHttpFirewall.getFirewalledRequest(StrictHttpFirewall.java:336) at org.springframework.security.web.FilterChainProxy.doFilterInternal(FilterChainProxy.java:194) at org.springframework.security.web.FilterChainProxy.doFilter(FilterChainProxy.java:178) at org.springframework.web.filter.DelegatingFilterProxy.invokeDelegate(DelegatingFilterProxy.java:358) at org.springframework.web.filter.DelegatingFilterProxy.doFilter(DelegatingFilterProxy.java:271) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:93) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:541) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:139) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:343) at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:367) at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:868) at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1639) at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(Thread.java:748)
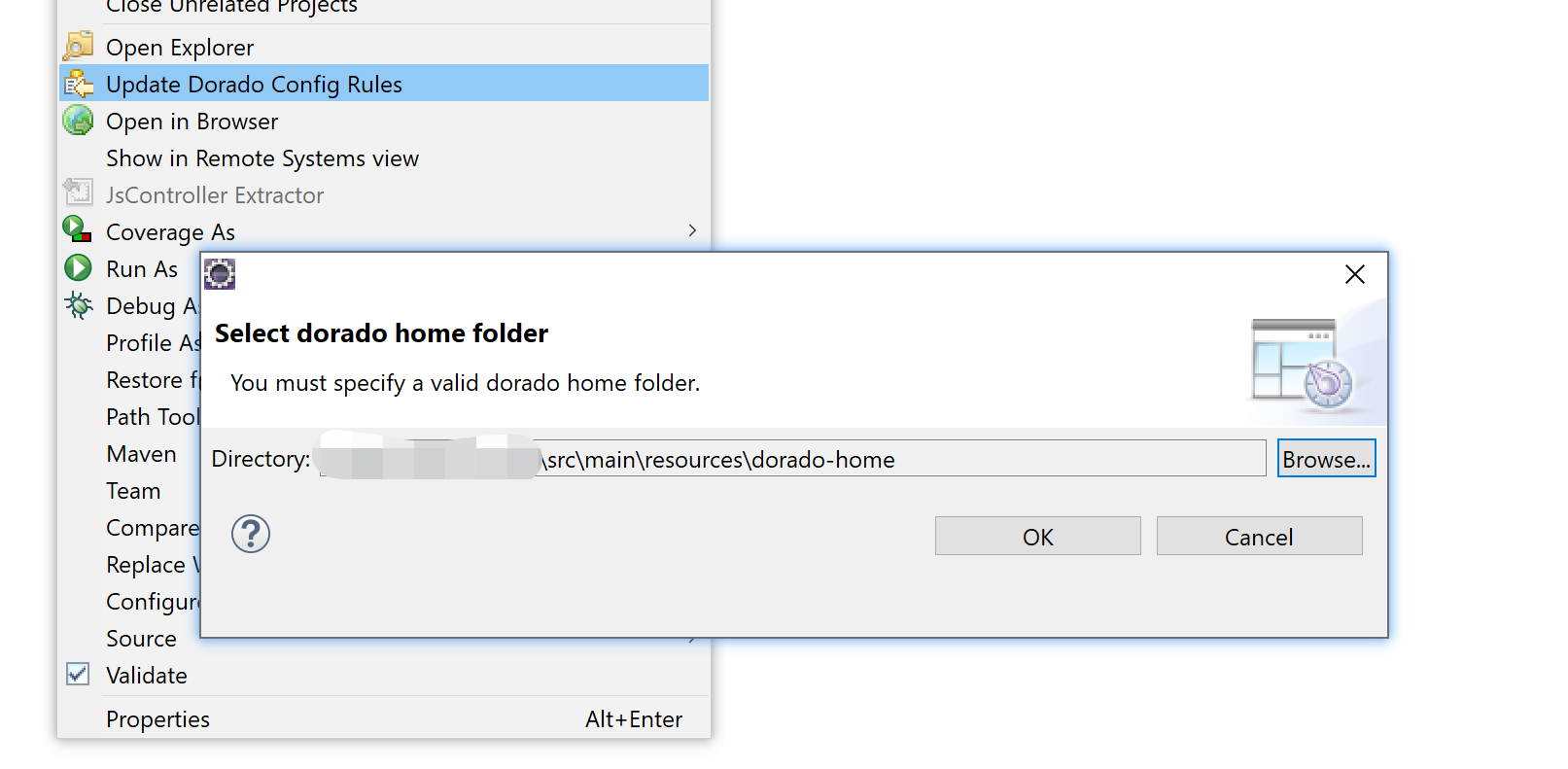
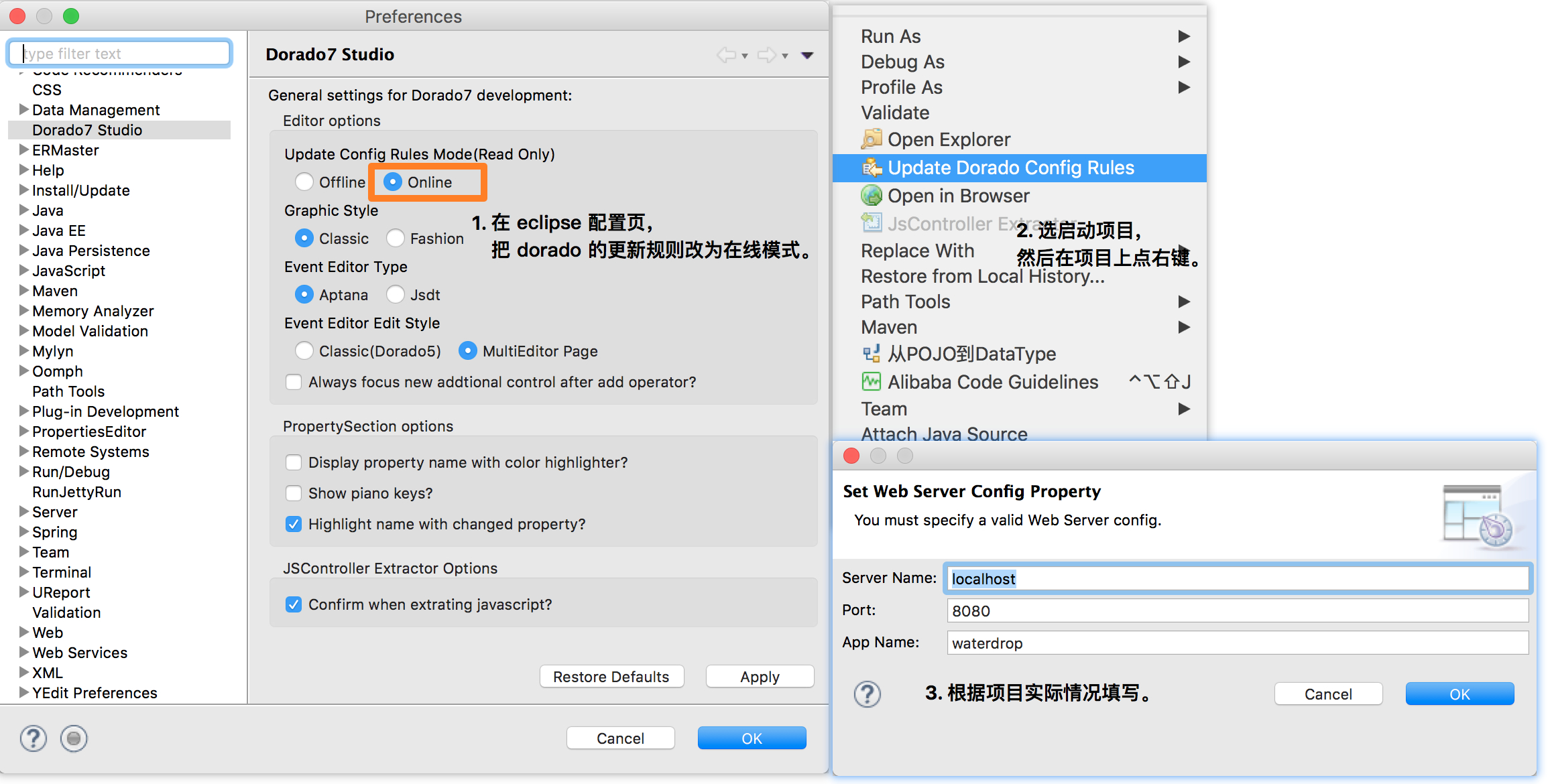 在线模式下 ServerName对应着域名或ip, Port就是端口号, App Name就是contextpath,如果为空可以不填。图片中是示例访问地址为:
在线模式下 ServerName对应着域名或ip, Port就是端口号, App Name就是contextpath,如果为空可以不填。图片中是示例访问地址为:  例如:
例如: