JavaScript 浮点怎么算都算不对。
小不的笔记
时间之外的往事
MacOS 微信获取视频号视频地址
原理参考自WeChatDownloader,基于内存搜索实现的视频号的视频地址获取。Windows也可以去这里下载工具。
在视频号播放视频的时候,在微信的内存中搜索https://finder.video.qq.com/251/20302/stodownload?encfilekey= 找到的URL大概率就是视频的地址呢。 MacOS可以使用免费开源的Bit Slicer ,类似金山游侠用来查看和修改内存的。 先选择进程WeChat, 然后类型选16-bit String, 符号保持 equals 不变,然后搜索框内输入https://finder.video.qq.com/251/20302/stodownload?encfilekey= ,视频号开始播放视频之后,点回车开始搜索。 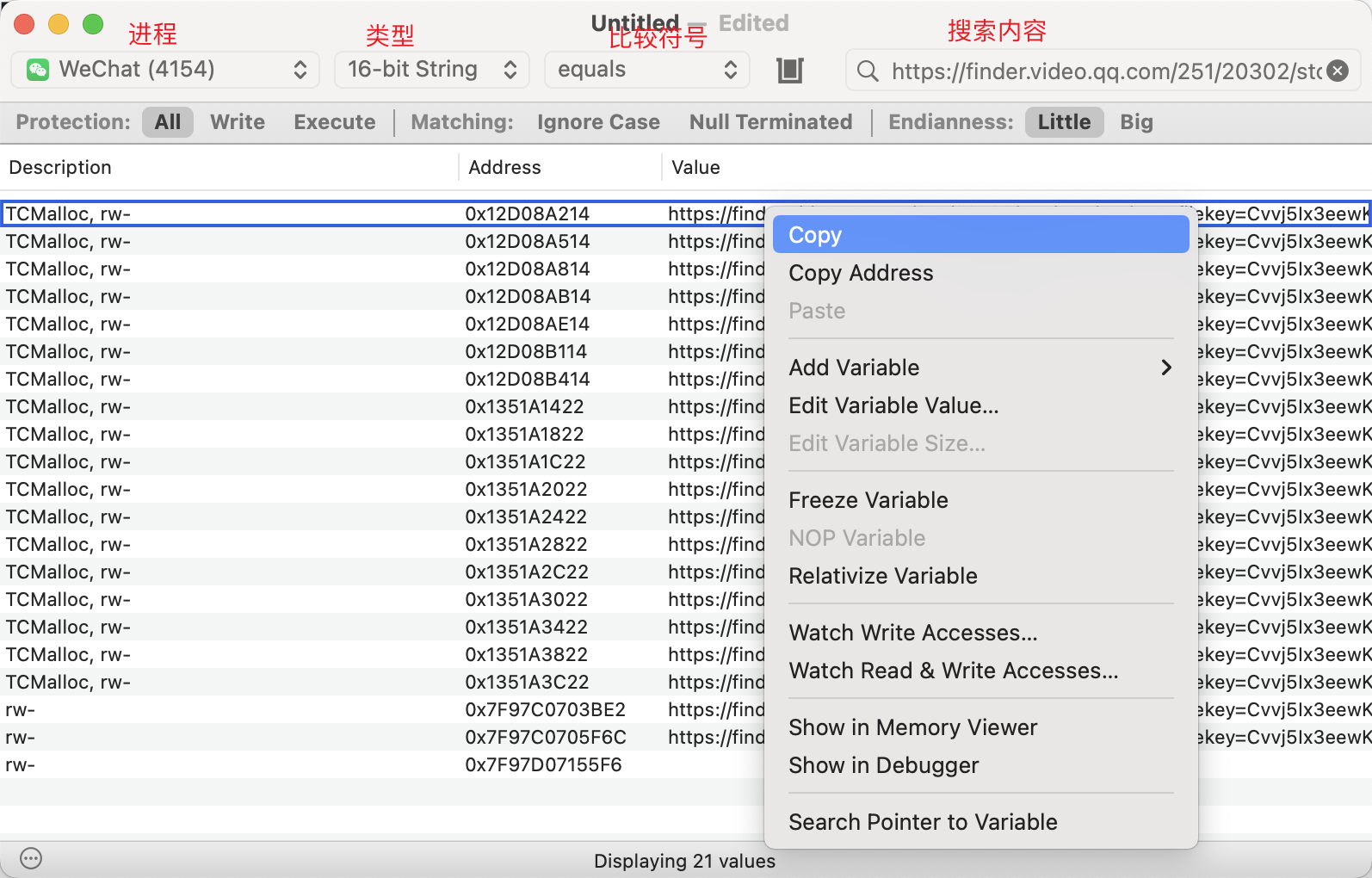 很快就会搜索出来所有包含上述URL的内存。在第一条上点右键,选择Copy,然后打开一个文本编辑器,粘贴,会得到类似如下的内容, 其中从 https开始到 taskid=0就是视频的URL了,复制一下去浏览器打开试试。如果第一条不是,可以试试其它的。
很快就会搜索出来所有包含上述URL的内存。在第一条上点右键,选择Copy,然后打开一个文本编辑器,粘贴,会得到类似如下的内容, 其中从 https开始到 taskid=0就是视频的URL了,复制一下去浏览器打开试试。如果第一条不是,可以试试其它的。
Windows7 安装 IE10
虽然现在已经2022年,Windows7已经停止安全更新两年了。但是在跟银行或者政府打交道时,IE10有时候又是一个唯一的选择。
微软官方虚拟机
在低频使用的情况下微软官方虚拟机是最好的选择,而且微软官方还提供了多种类型的虚拟机供使用,不用担心病毒木马后门什么的。不过这些虚拟机会在90天后过期,使用之前做一个快照,等到期之后再恢复一下就好了。 支持的虚拟机类型: - VirtualBox - Vagrant - VMware (Windows, Mac) - HyperV (Windows) - Parallels (Mac) 不仅有IE10还有更多的其它IE与Windows的组合: - IE8 on Win7 (x86) - IE9 on Win7 (x86) - IE10 on Win7 (x86) - IE11 on Win7 (x86) - IE11 on Win81 (x86) - MSEdge on Win10 (x64) Stable 1809 下载地址:Virtual Machines - Microsoft Edge Developer
离线安装IE10
由于各种原因不希望使用微软官方虚拟机,也可以自行安装IE10。
前置条件
要保证Windows7已经安装了一下补丁: - Windows 7 Service Pack 1 - KB2729094 现提供对 Windows 7 和 Windows Server 2008 R2 中 Segoe UI 符号字体的更新 - KB2731771 已推出针对 Windows 7 或 Windows Server 2008 R2 中的本地时间和 UTC 转换的新 API 更新 - KB2670838 有可用的 Windows 7 SP1 和 Windows Server 2008 R2 SP1 的平台更新
根据文档还需要一个补丁 KB2533623 但不知道为什么微软把这个补丁下载移除了。 测试下来没有这个补丁也没影响。
安装IE10
IE 10的安装包也被官方删除了。只能从网上收集三方来源的。 前置条件都安装好之后,就可以安装IE10呢。如果没有安装好会停留在“正在下载所需更新。。。” 很久。 安装找到系统对应的安装包,双击就好了。 链接: https://pan.baidu.com/s/1MPe0VCOZHGYkg46G5Uww9g?pwd=iprg 提取码: iprg
Java7 HTTPS 支持 TLS 1.1 TLS 1.2
在Java SE 7 中,SunJSSE 支持TLS 1.1 and TLS 1.2。但是考虑到当时(since 2011)很多服务器对这两个协议支持的不好,就把这两个版本的协议禁用,默认使用TLS 1.0。 如果要启用这两个协议的支持也很简单:
设置系统属性
https.protocols
指定Java HTTPS连接(HttpsURLConnection 或 URL.openStream())使用的协议版本。
1 | -Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2 |
或
1 | System.setProperty("https.protocols", "TLSv1,TLSv1.1,TLSv1.2"); |
验证代码
1 |
|
jdk.tls.client.protocols
指定TLS的默认版本(since Java8,Java7u95,Java6u121)。
1 |
|
验证代码
1 |
|
如何不影响全局
修改系统属性,整个JVM都会受到影响。如果希望把影响范围降到最低,可以通过定制HttpClients的方式。
1 | SSLContext sslContext = SSLContexts.createDefault(); |
验证代码
1 |
|
unable to find valid certification path to requested target
如果拿我的域名做测试,还会报这个异常。因为我的HTTPS证书是申请LetsEncrypt的。JDK7发布时,LetsEncrypt还不存在,所以JDK7的证书里不识别它,需要手动加载一下。
1 | wget https://letsencrypt.org/certs/lets-encrypt-r3.pem |
>= 7u151, 8u141 就不需要手动加载证书了。 $JAVA_HOME 需要指向JDK7或其它低版本JDK。
参考链接: Java Cryptography Architecture Oracle Providers Documentation for Java Platform Standard Edition 7
从⽅不是方到Unicode正规化NFD, NFC, NFKD, NFKC
在做PDF解析的时候,发现甲方的方字一直匹配不上。解析出来的⽅字的Unicode值\u2F45,而我正常打字打出的方字Unicode值是\u65B9。 之前也遇到过从PDF中复制出来的字,看着像这个字其实是另一个字,一直以为是PDF源文件的问题没有深究。这次PDF是我用Word另存为生成的,可以稳定复现问题,有机会深入研究。 “方”(\u65B9)字在原始Word文档里可以搜的到,说明原始文件没有问题。在PDF阅读器里也能搜到,唯独我的通过pdfbox解析,只能解析出”⽅”\u2F45。通过unicode-table 发现2F00-2FDF是康熙字典部首段。说明这些字与部首之间存在某种关联,这些关联还是这些编辑器及阅读器都在遵循的。
Unicode Normalization
这个关联就是Unicode Normalization,Unicode正规化。Unicode 还有一个特点,等价性(Unicode equivalence)。由于Unicode收录了很多字符,而这些字符功能上会和其他字符或者字符序列等价。因此,Unicode将一些码位序列定义成相等的。Unicode提供了两种等价概念:标准等价和兼容等价。
标准等价
保持视觉上和功能上等价。例如 ‘≠’ (\u2260) 标准等价于 ‘=’ 和 ‘̸’(\u003d\u0338)的组合。区别在于一个是一个字符,一个是两个字符。
兼容等价
兼容等价比标准等价范围更广,也更关注纯文字的等价,并把一些语义上的不同形式归结在一起。 如果字符是标准等价,那么他们一定是兼容等价,反之就不一定了。 例如 ‘㊋1a’ (\u328b\uff11\uff41) 带圆圈的火,全角的数字和字母兼容等价与 ‘火1a’ (\u706b\u0031\u0061)。
四种组合
在此基础之后Unicode又定义了两种形式,完全合成,完全分解。由此组合出四种形式: NFC、NFD、NFKC、NFKD。 C 代表 Composition 就是组合的意思 D 代表 Decomposition 就是分解的意思。 K 代表 Compatibility 就是兼容等价模式,如果不带K就是标准等价。 分解和组合主要用于是字母符号。汉字我没找到可以分解和组合的例子。汉字的兼容等价场景就很多,除了我遇到的部首⽅,还有 ㊥ 与 中、 ㍿ 与 株式会社、全角与半角。。。 NFC 以标准等价组合。 NFD 以标准等价分解。 NFKC 以兼容等价组合。 NFKD 以兼容等价分解。 所以这个时候,我们只需要用兼容等价(NFKC/NFKD)的方式就可以把部首转化为文字。 Java代码:
1 | Normalizer.normalize("⽅", Form.NFKC); |
JavaScript代码:
1 | '⽅'.normalize('NFKC') |
可以在浏览的控制台直接尝试如下代码验证
1 | // 字符长度 1 |
产生原因的推测
Unicode Normalization 并没有提供一个把文字转化为部首的方案,理论上来讲文字也不可能无损的转化为部首。出错的地方使用的字体是苹果的苹方字体。该字体下两个方字长相一模一样。所以推测是字体的原因,PDF引入外部字体时为了保证各个平台下的一致性,都会做字体嵌入。有可能这两个字在苹方字体下它的内部编码是一致的,转化为PDF再还原出来时Unicode值变成了更靠前的值(部首)。 创建一个新的Word文档,写两行甲方。第一行用宋体,第二行用平方,另存为PDF,再解析。得到
\u7532\u65b9 \u7532\u2f45 PDF 内部存储文字并不是以Unicode的方式,而是有独立的编码方式 ANSI、Identity-H等。然后在用户复制文字的时候通过
/ToUnicode转换出Unicode编码。
参考链接
Normalization Charts https://www.unicode.org/charts/normalization/chart\_Latin.html 在线unicode转中文,中文转unicode-BeJSON.com https://www.bejson.com/convert/unicode\_chinese/ Normalizing Text (The Java™ Tutorials > Internationalization > Working with Text) https://docs.oracle.com/javase/tutorial/i18n/text/normalizerapi.html Unicode等价性 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/Unicode%E7%AD%89%E5%83%B9%E6%80%A7 miscellaneous/浅谈pdf乱码.md at master · yunhailuo/miscellaneous https://github.com/yunhailuo/miscellaneous/blob/master/%E6%B5%85%E8%B0%88pdf%E4%B9%B1%E7%A0%81.md
mysql create table
建表
1 | CREATE TABLE table [IF NOT EXISTS] ( |
CREATE TABLE … LIKE …
基于一张表来创建另一个表 一模一样复制表结构, 包括主键、索引、默认值等信息。
1 | CREATE TABLE t2 LIKE t1; |
复制表和数据,还希望完整保留主键、索引、默认值等信息。
1 | CREATE TABLE t2 LIKE t1; |
CREATE TABLE … SELECT
可以认为是 CREATE TABLE 语句 追加一个 SELECT 语句用来填充数据。 CREATE TABLE 中的表定义的列 和 SELECT 列如果不存在,SELECT 中的列会追加到表的最后。 SELECT 列类型与CREATE TABLE中定义不一样,以CREATE TABLE定义为准。 创建表且复制数据,但是不需要主键、索引、默认值等信息。
1 | CREATE TABLE t2 [AS] SELECT * FROM t1; |
只创建表, 其他什么都不需要。
1 | CREATE TABLE t2 [AS] SELECT * FROM t1 LIMIT 0; |
复制表和数据,只想保留主键
1 | CREATE TABLE t2 (PRIMARY KEY (`ID`)) [AS] SELECT * FROM t1; |
删表
1 | DROP TABLE t1; |
删除存在的表
1 | DROP TABLE IF EXISTS t1; |
参考链接
CREATE TABLE CREATE TABLE … LIKE Statement CREATE TABLE … SELECT Statement
BDF2’s dependencyManagement
BDF2’s dependencyManagement
根据自己需要自行删改项目
1 | <properties> |
应用端口规划
前言
Kubernetes 时代基本不需要担心端口冲突了,但是像我现在公司因为历史原因很难迁移至Kubernetes, 如果一台机器上部署多个应用的情况下,依旧需要对应用端口做一个规划。 云服务器基本上都是按CPU和内存收费。我们的应用基本都是Java应用比较耗内存,开发及测试环境对CPU基本没有需求。内存是固定分配的很难分配,CPU是弹性分配。从节省成本的角度,买CPU少,内存大的服务器,尽可能的在一台服务器上部署更多的应用服务。 一个使用dubbo的Tomcat应用可能用会用到: HTTP端口, Shutdown端口, AJP端口, dubbo端口,JMX Remote 端口, JDWP端口(The Java Debug Wire Protocol)… 早期没有对应用的端口做任何规划,都是使用默认端口,默认端口不行就+1, +2。为了模拟生产环境,测试环境下也都是多节点部署,在部署到不同的服务器时,可能某些端口已经被占用了,导致同一个应用在不同的服务器下,相同的服务使用了不同的端口,毫无规律可言。这个时候就需要规划一下服务器的端口分配。
TCP协议端口的特点:
- TCP/IP端口范围是0-65535
- Linux要求只有root账号才能监听<1024的端口
- 大多数Linux发行版使用的临时端口范围是 32768–60999
- 大多数软件喜欢使用4字数字作为默认端口号:MySQL(3306), Tomcat(8080),Prometheus(9090)等等
规划方案
所以在规划应用端口时尽量避开常用的端口以减少冲突的可能。我现在应用的端口从 10000起,前四位是应用标识,最后一位是外对外开放端口标识。这样,
4位应用标识:
- 从1000到6652,理论上可以拥有5552个应用标识(6552-1000), ()。
- 可以在一定程度上和Apollo配置中心的appId相呼应
1位开放端口标识:
- 0-9,每个应用都可以分到10个端口
- 如果不够用可以通过占用多个应用标识的方式,分配到更多的端口。
- 可以根据自己的实际情况来分配端口标识
像我们公司应用基本都会提供HTTP服务,HTTP端口标识为0;HTTP Management端口就标识为1;为了跟老系统互通很多项目都引入了dubbo,dubbo端口标识为2;JMX Remote端口标志是3。 如果应用标识为1001、1002的应用对外端口如下:
应用
应用编号
HTTP
HTTP Management
dubbo
JMX Remote
JDWP
…
app1
1001
10010
10011
10012
10013
10014
1001X
app2
1002
10020
10021
10022
10023
10024
1002X
这样就可以保证在任一一台服务器部署的服务所使用的端口一致且不会冲突,方便部署运维维护。
HTTP keep-alive
什么是HTTP keep-alive
HTTP keep-alive, 准确的说是HTTP持久连接(HTTP persistent connection),是使用同一个TCP连接来发送和接收多个HTTP请求和响应。 持久连接的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销。 在 HTTP/1.1 中,所有的连接默认都是持久连接,但在 HTTP/1.0 内并未标准化。 对于支持keep-alive的HTTP服务器,回应的HTTP头里:
1 | Connection: keep-alive |
当然我们并不希望这个期限是永远,需要给他加一个期限, 服务端在回应的HTTP头里加入Keep-Alive,单位是秒。
1 | Connection: keep-alive |
在Nginx下配置keep-alive
做为HTTP Server Nginx默认已经支持keep-alive。 但是根据实际需要,可以调整以下参数:
keepalive_disable
针对某些浏览器禁用
keep-alive功能,可选的值有: msie6, safari等等。
keepalive_requests
一个TCP连接可以处理的HTTP请求的数量限制,达到限制就关闭连接。默认值1000 (从版本1.19.10开始,默认值调整为100)
keepalive_time
一个TCP连接的最长存活时间,默认1小时(从版本1.19.10开始新增的参数)
keepalive_timeout
keep-alive的超时时间,一个TCP连接。
keepalive_timeout
keepalive_timeout 有两个参数:第一个参数是服务端的TCP连接的超时时间,如果值是0则关闭Keep-Alive功能;第二个参数是可选的,是在控制响应头里的Keep-Alive: timeout=time的值,这两个时间值可以不一样。建议在设置时第一值略大于第二个。
Syntax: keepalive_timeout timeout [header_timeout]; Default:
keepalive_timeout 75s; Context: http, server, location
1 | keepalive_timeout 75s 60s |
TCP keepalive
TCP是面向连接的。创建一个TCP连接,客户端和服务端需要经历三次握手,一旦建立它的期限就是永久,除非其中一方发起关闭。 理想状态下,客户端与服务端建立连接就可以一直用下去,但是在真实的互联网世界没有这么理想: NAT网关、防火墙、代理服务器等网络设备可能会清理空闲的连接; 也有可能其中一方突然崩溃、网络断开来不急通知对方关闭连接;或者其他意外,导致其中一方或双方的连接就一直永久保留在那里。 客户端,随着应用的关闭,系统会自动回收应用创建的连接。这个不处理似乎影响也不太大。 服务端,软件都是长期运行的,没办法通过软件的关闭来实现连接的回收。在Linux里一个空闲的TCP连接占用将近4k内存,大量的空闲连接积攒下来消耗不少内存。而且服务端一直不释放可能会导致TCP创建连接失败。所以在应用层基本都会有一个超过一定时间不使用主动关闭TCP连接的机制。
TCP keepalive 可以做什么
这个时候我们就会发现TCP keepalive似乎是可有可无的,确实在TPC连接中keepalive是默认不开启的。不过我们可以通过 TCP keepalive做这些事情:
1. 检测断掉的连接
keepalive在一定的间隔里通过连接发送一个信号,如果在指定的时间内收到回应就可以确认连接还是通的;如果指定的时候还没收到回应就启动重试;如果重试了最大重试次数内还是没收到回应,那么就判定连接不通了,就主动关闭连接。
2. 防止因为没有网络活动而导致连接的断开
NAT网关、代理服务器、防火墙等等会清理他认为不活动的连接,keepalive的周期性发送信号可以保持连接处于持续活动状态。Linux NAT网关的连接保持时间默认是1天,阿里云NAT网关连接的老化时间是900秒也就是15分钟,这也产生过一个生产事故。
如何在Linux下使用 TCP keepalive
Linux 原生支持TCP keepalive,并提供了三个用户参数:
tcp_keepalive_time默认值7200s(2小时),就是连接空闲多久,开始发keepalive 探测包。tcp_keepalive_intvl默认值75s,后续 keepalive探测包的时间间隔。tcp_keepalive_probes默认值9,发多少keepalive探测包没有回应,就认为连接已经死了需要通知应用层。
简易流程是这样的:
- 客户端创建启用keepalive的TCP连接
- 如果连接在
tcp_keepalive_time时间内一直静默,那么发一个空的ACK包,也就是keepalive探测包。 - 服务端是否回应这个ACK?
- 没有回应
- 等待
tcp_keepalive_intvl秒,然后发另一个ACK包 - 重复上一步,直到发了
tcp_keepalive_probes次ACK包。 - 到了这个点还是没收到回应,那么发送一个
RST包,然后关闭连接。
- 等待
- 收到回应,那么回到第二步
- 没有回应
如何修改参数
procfs是一个伪文件系统,通过它可以查看或修改内核参数。 查看
1 | cat /proc/sys/net/ipv4/tcp_keepalive_time |
修改
1 | echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time |
简单明了,但是不太适合大量的参数的管理,所有Linux还提供了一个辅助的工具sysctl。 把procfs路径里的/proc/sys/删掉剩下的 / 替换成 . 就可以了。 sysctl variable查看变量的值。 sysctl -a打印所有变量的值
1 | sysctl net.ipv4.tcp_keepalive_time |
需要修改的时候就用sysctl -w variable=value的方式
1 | sysctl -w net.ipv4.tcp_keepalive_time=600 \ |
要注意的是这些修改系统重启之后都会失效的,如果希望重启之后依然生效。就需要把配置写入/etc/sysctl.conf或者在/etc/sysctl.d/目录内创建一个.conf文件并写入配置。这样Linux系统再启动时就会加载并应用这个配置。
应用内
keepalive默认是不开启的,需要主动指定.
Java
1 | // BIO |
Does a TCP socket connection have a “keep alive”? https://newbedev.com/does-a-tcp-socket-connection-have-a-keep-alive TCP Keepalive HOWTO https://tldp.org/HOWTO/html\_single/TCP-Keepalive-HOWTO/